The following experiments address the question of what the mechanism underlying access to words’ meaning is. What type are the accessed representations? Are they word-specific? As of present, these questions are addressed using the EEG/ERP technique.
Szewczyk & Federmeier (2022) Journal of Memory and Language
[paper] [code & materials] [data]
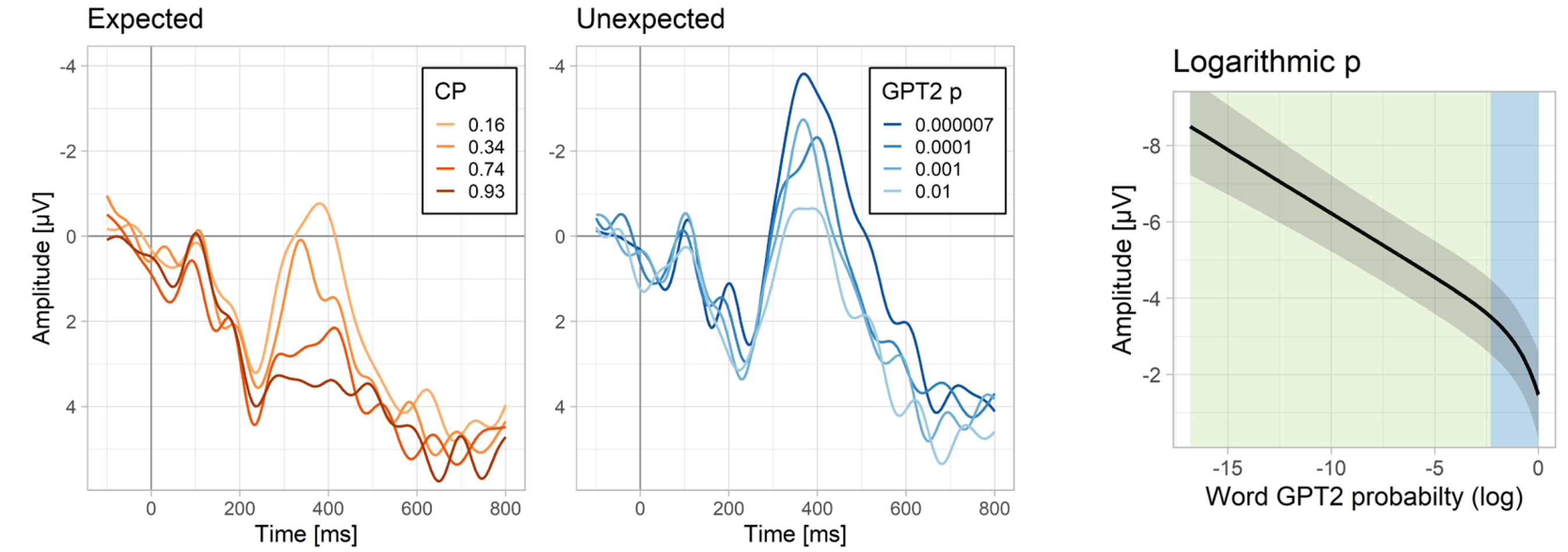
In typical ERP studies, the N400 is measured by contrasting congruent words (with cloze probabilities; CP > 0) and incongruent words (CP = 0). The classical finding is that the N400 amplitude to congruent words varies as a function of their cloze probability. In this study, we employed a deep learning language model (GPT-2) to estimate the probability of unpredictable and incongruent words, to see whether the N400 will vary as a function of their (im)probability. Across five datasets, our findings indicate that:
- There is at least as much variation in N400 amplitude to congruent, as to incongruent words
- Overall, the amplitude of the N400 is best modelled by using the logarithm of word probability
- However, within the 300-400ms, N400 is also influenced by linear probability
We conclude that:
- The logarithmic effect reflects facilitation of semantic features by the context
- In cases where linear probability is high, the contextually activated semantic features are sufficient to identify a specific word. In such cases, the features of the word that are not relevant for the current context also get activated. The linear effect reflects this additional activation of these features.
Szewczyk & Schriefers (2018) Language, Cognition and Neuroscience
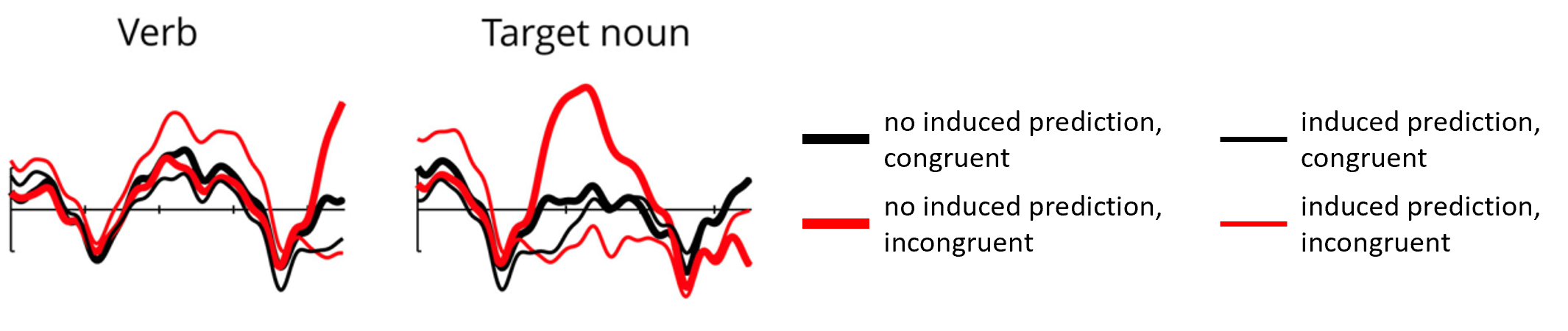
A prominent theory of the N400 assumes that the component’s amplitude is a function of the degree of prior activation of a word’s representations in semantic memory (Kutas & Federmeier, 2000). The amplitude is reduced for congruent words because the previous context already activated a large part of the word’s meaning. In this study, we explicitly tested this hypothesis. We manipulated a target word’s congruity in a sentence. Additionally, in half of the sentences, we artificially induced prediction of the target word by informing participants to expect it in the upcoming sentence.
We discovered that informing participants of the expected word completely nullified the N400 effect for incongruent words. The N400 was only triggered when there was no prediction induced for the incongruent target word.
Interestingly, we observed that when before the critical sentence the prediction for the target word was artificially induced, these words’ representations got accessed at a preceding verb.
In conclusion, our findings confirm that the manner of activating the word’s representations does not matter. Once the representations got activated, accessing the word’s meaning will lead to a reduced N400.